变量分三种,计量(数值变量、连续变量、定距变量等不同叫法)、等级(有序)和计数(分类、名义),因此变量的相关就有不同的形式。 (二)Spearman相关:双变量不符合正态分布或者一个不符合正态分布、或者分布不清资料。对于服从Pearson相关系数的数据也可以计算Spearman相关系数,但统计效能比Pearson相关系数要低一些(不容易检测出两者事实上存在的相关关系)。 (二)对于行和列都包含已排序值的表,请选择伽玛(对于 2 阶表,为零阶;对于 3 阶到 10 阶表,为条件)、Kendall 的 tau-b和Kendall 的 tau-c。要根据行类别预测列类别,请选择Somers 的 d。 (1)伽玛 (Gamma).两个有序变量之间的对称相关性测量,它的范围是从 -1 到 1。绝对值接近 1 的值表示两个变量之间存在紧密的关系。接近 0 的值表示关系较弱或者没有关系。对于双向表,显示零阶伽玛。对于三阶表到 n 阶表,显示条件伽玛。 (2)Somers d.两个有序变量之间相关性测量,它的范围是从 -1 到 1。绝对值接近 1 的值表示两个变量之间存在紧密的关系,值接近 0 则表示两个变量之间关系很弱或没有关系。Somers 的 d 是伽玛的不对称扩展,不同之处仅在于它包含了未约束到自变量上的成对的数目。还将计算此统计的对称版本。 (3)Kendall 的 tau-b (Kendalls tau-b).将结考虑在内的有序变量或排序变量的非参数相关性测量。系数的符号关系的方向,绝对值强度,绝对值越大则表示关系强度越高。可能的取值范围是从 -1 到 1,但 -1 或 +1 值只能从正方表中取得。 (4)Kendalls tau-c (Kendalls tau-c).忽略结的有序变量的非参数相关性测量。系数的符号关系的方向,绝对值强度,绝对值越大则表示关系强度越高。可能的取值范围是从 -1 到 1,但 -1 或 +1 值只能从正方表中取得。 (一)列联系数(contingency coefficient):等于卡方/(卡方+n),其值介于0-1之间,越大说明相关性越强。 (二)Phi and Cramers V:phi等于卡方/N,越大说明相关性越强,Cramers V是Phi的一个调整,绝对值越大,说明相关性越强。 用于反映自变量对因变量的预测效果,即知道自变量取值时对因变量的预测有多少改进,或者说知道自变量的取值时期望预测误差个数减少的比例,Lambda将误差定义为列(行)变量预测时的错误,其预测值是基于个体所在行(列)的众数。值为 1时表明知道了自变量就可以完全确定因变量取值,为 0时表明自变量对因变量完全无预测作用。 其值介于 0~1之间,和 lambda类似,也用于反映当知道自变量后,因变量的不确定性下降了多少(比例),只是在误差的定义上稍有差异。以熵为不确定性大小的度量指标,共会输出行变量为自变量、列变量为自变量、对称不确定系数三个结果,后者为前两者的对称平均指标。 希望测量一个名义变量和连续变量间的相关程度时,还可以使用一个叫做 Eta的指标,它所对应的问题以前是用方差分析来解决的。实际上,Eta的平方表示 由组间差异所解释的因变量的方差的比例,即 ss组间/ss总。范围在 0 到 1 之间的相关性测量,其中 0 值表示行变量和列变量之间无相关性,接近 1 的值表示高度相关。Eta 适用于在区间刻度上度量的因变量(例如收入)以及具有有限类别的自变量(例如性别)。计算两个 eta 值:一个将行变量视为区间变量,另一个将列变量视为区间变量。 当我们处理X和Y之间的相关性,可是Z与X和Y都有密切相关,因此Z的存在会影响X和Y之间真实的相关性,因此,需要控制Z后,研究X和Y之间的相关性。因此偏相关又叫做净相关。Z可能为X和Y的共同因素或者中介因素。偏相关为下图中A的部分。
有的时候,研究者想知道当去除了第三变量Z在X和Y变量中的效应后,两个变量X和Y之间的相关,在这种情况下,当用X来解释Y时,我们仅将Z从X中去除,而保持Y的“完整性”,在从X中去除Z后,完整的Y因变量和自变量X残差之间的相关,称为控制Z后的X和Y之间的部分相关。 当我们处理资料为两组资料之间的相关性时,就不能采用的相关性分析了,如一个班级学生的身体健康资料(身高、体重)与考试成绩(语文、数学、外语)之间的相关性,此时就是两组资料之间的相关性,应该采用典型相关分析。 距离相关时用于计算数值变量之间的距离相关性,通常不单独分析,一般为聚类分析或者因子分析的中间过程。 Distinces过程就可以用于计算记录(或变量)间的距离(或相似程度),根据变量的不同类型,可以有许多距离、相似程度测量指标供用户选择。但由于本模块只是一个预分析的过程,因此距离分析并不会给出常用的p值,而只给出各变量/记录之间的距离大小,以供用户自行进行判断相似性。
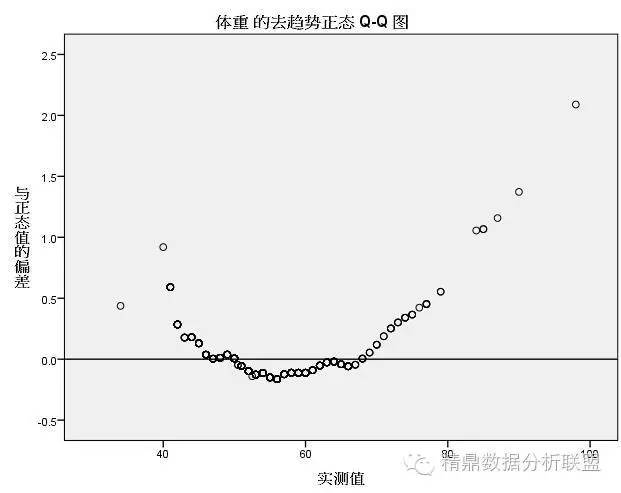
包括了双变量(Pearson、Spearman和Kendall)、偏相关、距离相关,还有典型相关(注典型相关以前小编都是通过编程实现的,可费劲了,SPSS23已经加载进菜单了,赞一个!!) 3.解读:直方图专门用于反映连续性资料(数值变量、计量资料)频数分布的,帮助我们探析数据分布的规律。看图需要结合经验,本例数据右侧拖尾大家基本都能看出来,但松哥认为还可能有点尖峭峰,意思是太尖了。当然后面我们继续会验证松哥的看法。 解读:所有点相连呈串,分布于参考斜线之上,则为正态,本例非常明显,很多点不在线上,因此应该不符合正态分布。
解读:虽然箱式图一般用于判定数据是否存在异常值,但如果细心,上方很多离群值,数据像大的方向拖尾,结果与直方图判读一致。 解读:茎叶图现在基本很少用啦!其命名似乎是根据形态,如果整个图逆时针转90度,不就是变相的直方图吗?也是反映分布形态的,但信息含量远大于直方图,大家请看倒数第二行,我解读一下,最左边的7是指右边的小数点后面有7个数字,发现4444555,确实7个。7.是茎,4444555是7个树叶,最后一行主干宽度是10,意味数字得放大10倍,意思是有4个74。3个75。就这样解读的。
解读:SPSS此处提供了两种检验,D检验和W检验。本例两种检验得到的P值均小于0.05,因此认为不符合正态分布。但是也会出现D检验和W检验不一致的情况,此时如何选择以前文章发过,此处不赘述!
峰度系数是用于判定分布是不是太尖或太平;偏度系数用于判定偏左还是偏右,这点很容易理解!如下图
本例的分析结果见下表,红色框中分别为峰度系数和偏度系数及其各自的标准误差;那么如何判断呢,比如看偏度判断=0.908/0.101约等于9,如果此值的绝对值大于1.96就认为偏,因为此处是正值,因此为正偏态(右偏态);峰度系数判断方法同样,正值为尖峭峰,负值为平阔峰。
解读:大家看下图,均值、中位数与众数在三种分布的关系如下,如果三者偏差太大,一般不可能符合正态分布。
一般正态分布的标准差不会大于均值的1/3,这是目测判断法哦,最终还是要经过检验,但如果标准差都大于均数,一般不太可能正态分布。 1.案例数据依旧同上。现在采用非参数的方法。SPSS-分析-非参数-单个样本K-S检验,弹出下图:
解读:单样本K-S检验可以验证四种分布,本例选择的是正态分布验证,非参数检验结果一般比较简单,大家看最后的P值=0.0000.05。因此,不符合正态分布哦! 延伸相关词: 陈小艺被曝姐弟恋,倒追小伙被当保姆,陆贞传奇演员表,人鱼情未了 电视剧,莫小棋三级,保拉的诱惑,李慧珍老公,luciano rivarola,如意剧情介绍电视猫,电视剧当狗爱上猫 |
友情赞助: